我们使用ollama 有一段时间了,Ollama是一个开源框架,主要用于在本地机器上运行和管理大型语言模型(LLM)。它有以下特点:
- 易用性:Ollama设计简洁,使得即使是非专业用户也能轻松部署和管理大型语言模型。它通过提供命令行界面和集成Docker容器来简化部署过程。
- 支持多种操作系统:Ollama支持MacOS、Linux以及Windows平台,这使得广泛的用户群体都能够使用这一工具。
- 丰富的模型库:Ollama支持多种大型语言模型,如Llama2、Mistral、Phi-2等,并且可以根据需要自定义或导入自己的模型。
- 功能齐全:除了基本的模型运行功能,Ollama还提供了模型创建、显示信息、推送到注册表等高级功能。此外,它还支持模型权重、配置和数据的捆绑包装,称为Modelfile,以优化设置和配置细节。
- 轻量级:Ollama在运行时占用的资源较少,这对于资源受限的环境尤其重要。
- 灵活的扩展性:Ollama不仅支持命令行操作,还可以与UI界面结合使用,方便用户快速搭建应用程序,如类似ChatGPT的应用。
- 社区和文档支持:Ollama拥有活跃的社区和丰富的文档资源,这有助于用户解决遇到的问题并学习如何更有效地使用该工具。
ollama 最新版本v0.1.33版本开始支持同时加载多个模型、单个模型同时处理多个请求了。这个功能的改进将会大大提高ollama易用性。这个2个功能是什么意思呢?之前我们在使用ollama 都是单模型单任务,也就是多个用户请求只能排队 前面处理完了,才能到后面的用户使用。另外用户模型使用也只能同时使用一个模型,这样对用户体验来说就有所不便了,今天给大家介绍的就是这2个新功能。
1.升级ollama
如果需要使用到ollama 这2个新功能需要升级到ollamav0.1.33 版本
ollama 下载地址 https://github.com/ollama/ollama/releases
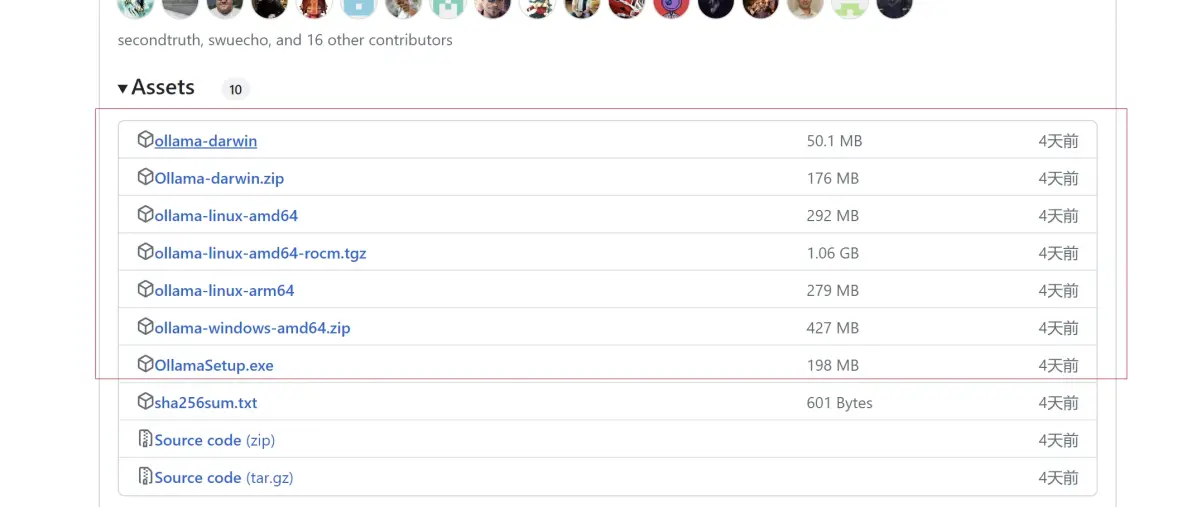
下载对应版本即可。我电脑上是使用windows ,后面就拿windows 举例
windows ollama 软件安装这个没上面好说的,一路next 点击安装即可。
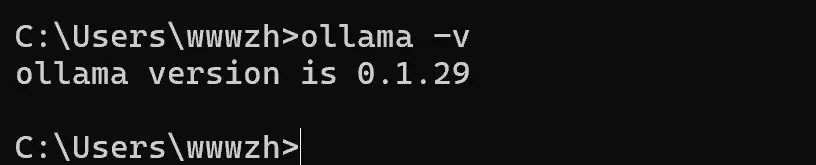
安装升级之前我们先检查本地版本
ollama -v
接下来下载OllamaSetup.exe 安装
安装完成后,我们在检查一下ollama 版本
ollama -v

cmd窗口中输入0.1.33 那么这个时候我们ollama 升级成功。
2 单个模型同时处理多个请求
这里介绍一下这个请求的参数OLLAMA_NUM_PARALLEL 这里可以设置我们多路请求数量比如我们这里设置2,这样2个用户同时请求就不需要等待了。
这里我们先测试一下不设置参数的请求情况。
启动ollama serve

这里我们什么参数都不设置直接启动。
加载一个模型
ollama run gemma:2b

我们开启2个窗口,同时输入内容
输入内容:请给我讲一个狼外婆的故事,字数不少于1000个字
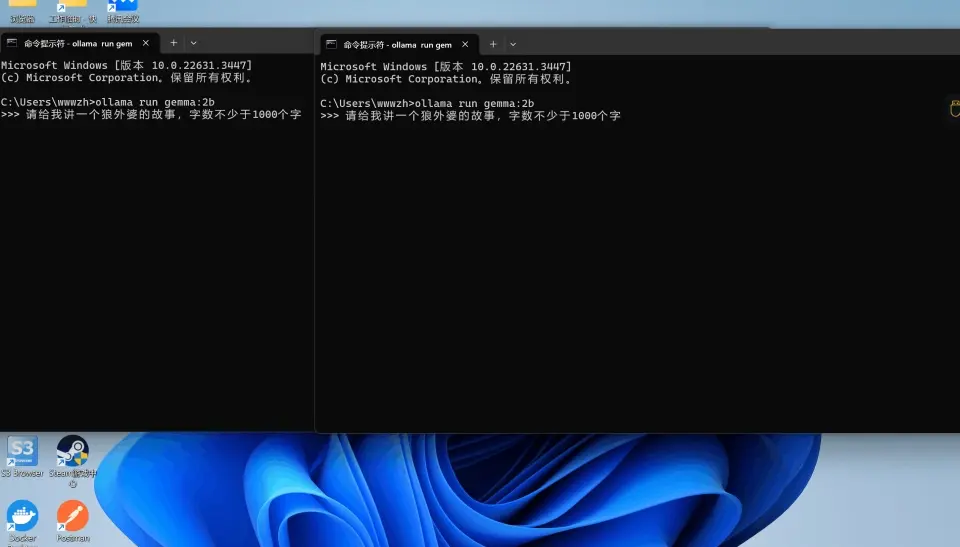
我们通过这个gif动画输出可以看到,同时输入2段对话,程序执行后,第一个聊天对话还没结束之前,第二聊天对话一直处于等待状态,这个就是我们之前说的单个模型单个请求。
下面我们重新启动ollama serve 增加并发请求参数OLLAMA_NUM_PARALLEL,启动命令如下
set OLLAMA_NUM_PARALLEL=2 ollama serve
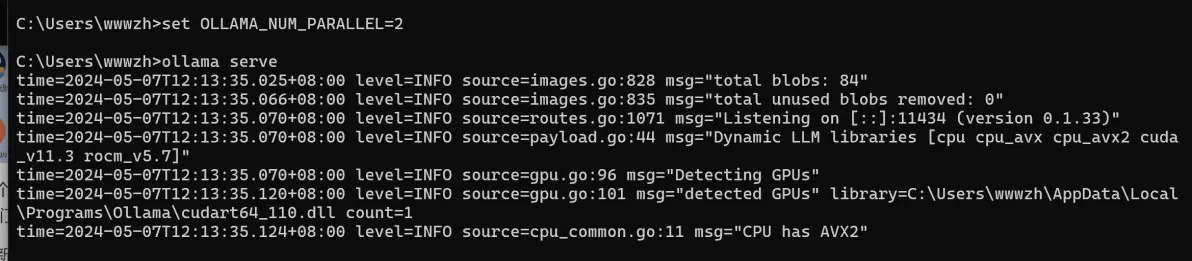
这个时候启动后模型就支持并发请求了,我们测试一下
输入内容:请给我讲一个龟兔赛跑的故事,字数不少于2500个字
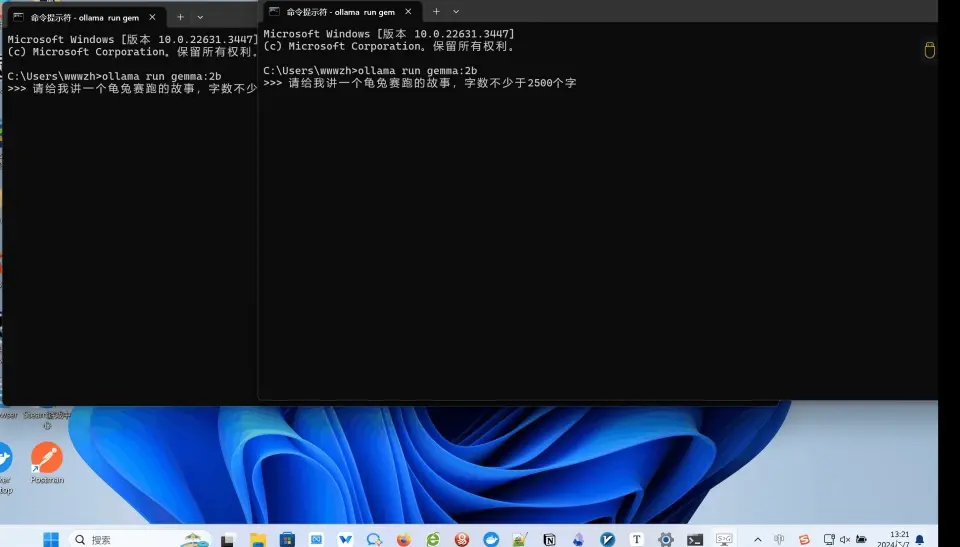
我们通过上面gif动画看到同时2个用户请求后,因为并发的数量设置2。是运行2个用户同时请求的,返回结果也是符合我们预期,ollama v0.1.33版本实现了多路并发请求。
3 多个模型同时处理多个请求
这个多模型加载需要通过另外一个请求参数设置OLLAMA_MAX_LOADED_MODELS 这里设置和并发数设置一样,设置大于1的数字这样就可以同时加载多个模型了。
单模型加载这里就不给大家演示了,因为我们主要是测试多模型加载是否成功,所以我们重点讲解多模型多用户加载。一般情况下多模型多并发请求经常会同时使用,所以我们将2个参数熟悉一并讲解
ollama serve 增加并发请求参数OLLAMA_NUM_PARALLEL和OLLAMA_MAX_LOADED_MODELS ,启动命令如下
set OLLAMA_NUM_PARALLEL=2 set OLLAMA_MAX_LOADED_MODELS=2 ollama serve
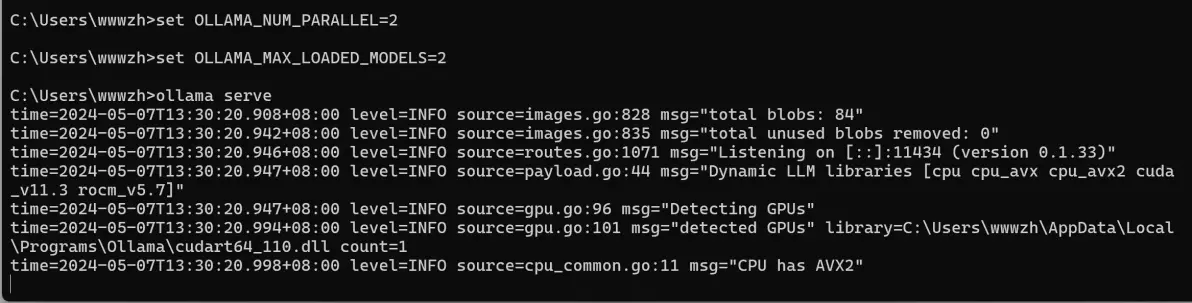
设置好2个参数后启动这样就支持了多模型多用户请求,下面我们测试验证一下。
加载一个模型
ollama run gemma:2b
加载另外一个模型
ollama run llama3:8b
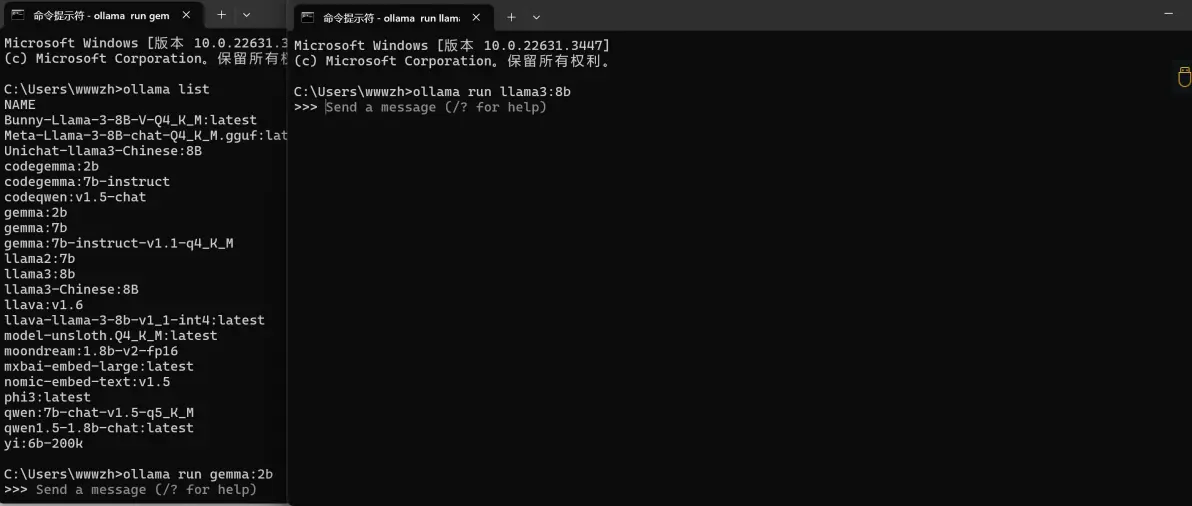
2个模型都加载内存中,我们查看一下显卡使用情况
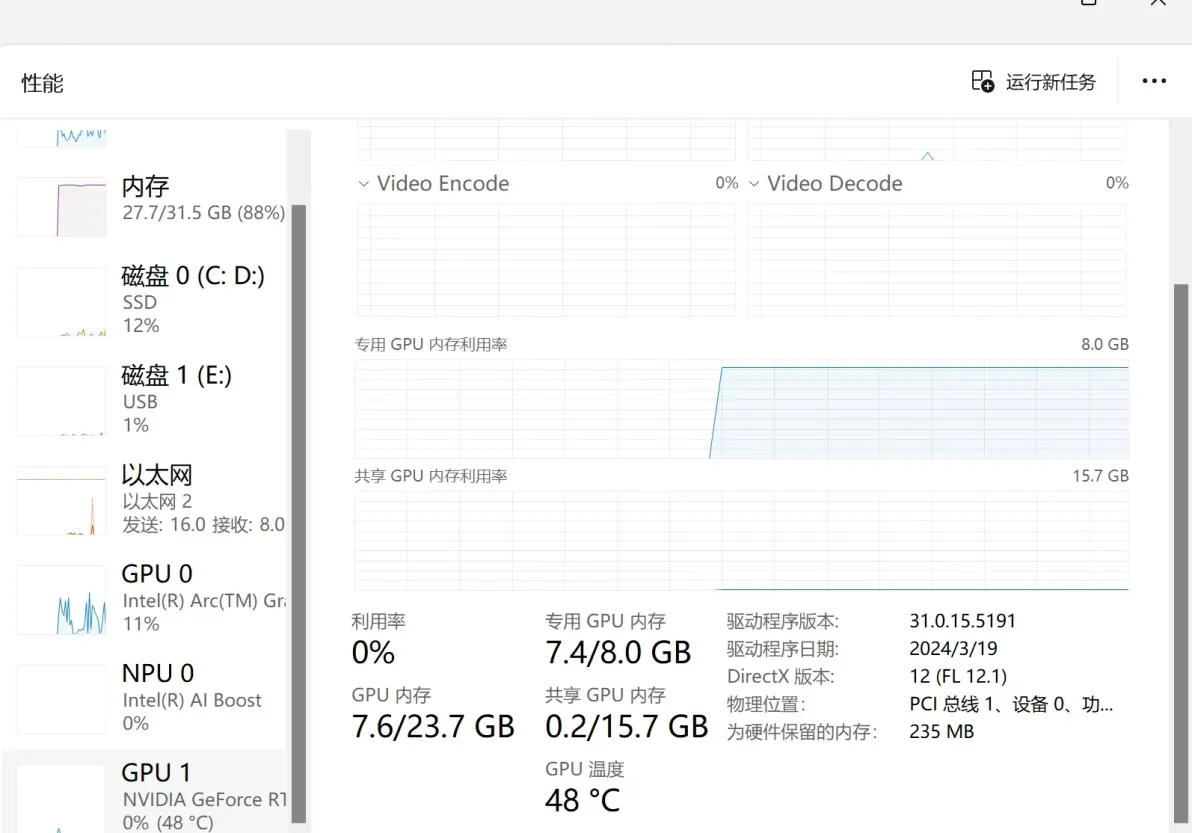
我这里用了gemma:2b 这个小模型大概消耗显存1.7G ,llama3:8b 大概消耗显存4.7G 2个累计大概占用7.4GB显存,还省一点留着对话聊天使用。
输入内容:请给我讲一个白雪公主和七个小矮人的故事,字数不少于2500个字

我们通过这个GIF动画可以看到我们使用2个模型 一个中文支持较好,一个中文支持不好,同时请求2个用户请求不同模型返回不同的信息,这样也就实现多模型多请求的操作了。
有的小伙伴可能看到我们在启动的时候通过set 方式设置参数,窗口关闭了后面参数设置就无效了。有没有办法永久设置呢?答案是肯定的的,我们可以将他设置到系统的环境变量中。
编辑账号的环境变量--环境变量 打开环境变量设置
用户环境变量中我们增加以上2个属性
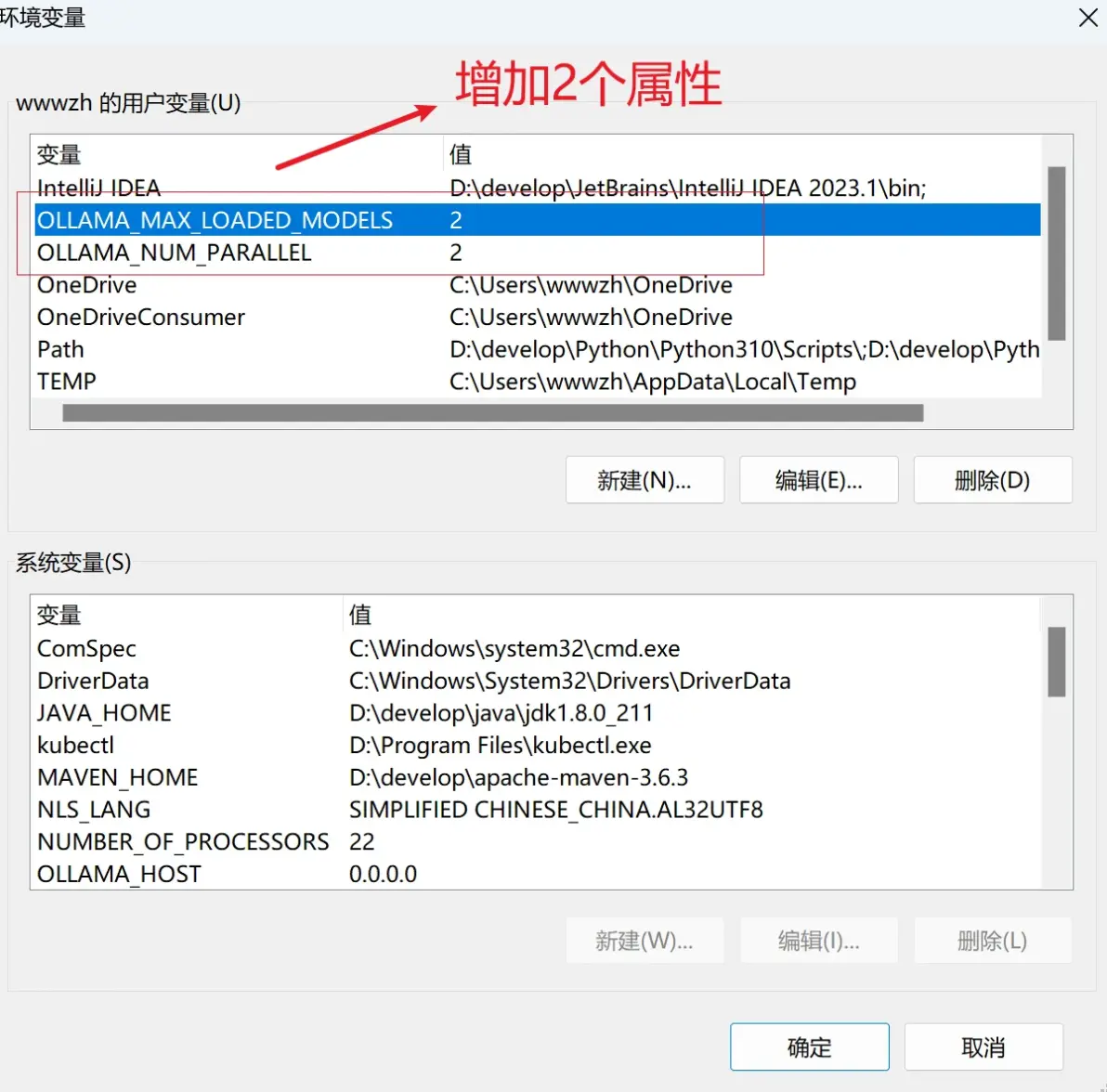
通过以上方式设置,下次启动ollama 就不需要局部设置这个属性了。
4 常见ollama 属性设置
我们在平时使用ollama过程中会遇到不少问题,比如模型镜像加载在C 盘有没有办法切换到其他盘符、启动ollama 只能127.0.0.1 不能使用IP 访问等问题。这些问题都是可以借助ollama 属性设置来解决。
1 OLLAMA_HOST=0.0.0.0 解决外网访问问题
2 OLLAMA_MODELS=E:\ollamaimagers 解决模型默认下载C 盘的问题
3 OLLAMA_KEEP_ALIVE=24h 设置模型加载到内存中保持24个小时(默认情况下,模型在卸载之前会在内存中保留 5 分钟)
4.OLLAMA_HOST=0.0.0.0:8080 解决修改默认端口11434端口
5.OLLAMA_NUM_PARALLEL=2 设置2个用户并发请求
6.OLLAMA_MAX_LOADED_MODELS=2 设置同时加载多个模型
以上就是我们常用到的属性,通过以上设置能够更加方便使用ollama.
5 总结:
Ollama是一个强大的工具,它通过简化部署过程、支持多平台、提供丰富的模型库和高级功能,以及优化资源使用,使得在本地运行大型语言模型变得更加容易和高效.今天的分享到这里结束了,感兴趣的小伙伴可以持续关注。